

With the large amount of data being generated by various computing systems around the world, parallel computing offers a solution to break the data into smaller chunks to be reassembled later.
While parallel computing works well for regular codes, graph algorithms are tougher to parallelise because of their inherent irregularity. To add to this problem, exploiting the parallelism of graph algorithms on various hardware is challenging. Also, the programmer would need to be an expert in the application domain in high-performance computing (HPC), and also in computing systems. Such highly qualified personnel are nearly impossible to find.
Therefore, one solution to this problem is to create a graph library, or a domain-specific language (DSL), which allows domain experts to express their algorithm using API (application programming interface) or high-level constructs, and the library or the DSL compiler taking care of generating high-performing code for the target hardware.
One of the limitations of graph DSLs or libraries, is that they target only a specific hardware architecture. The aim of this study is to ease the parallel programming burden when it comes to graph algorithms.

In this study, the authors Ms. Nibedita Behera, Mr. Ashwina Kumar, Mr. Ebenezer Rajadurai T, Mr. Sai Nitish, Mr. Rajesh Pandian M, and Prof. Rupesh Nasre from the Department of Computer Science And Engineering, Indian Institute of Technology (IIT) Madras, Chennai, India, have come up with a graph DSL called StarPlat, which allows a user to provide an algorithm specification of graph problems using its high-level graph specific constructs, and generates code for multiple backends (a backend is a data or an infrastructure that makes an application work) from the same algorithmic specification.
The constructs were carefully designed to abstract the parallelisation specific implementations from users, while ensuring generation of high performing graph codes. The compiler translates the DSL code to C/C++ programming language. Three different backends are used – OpenMP for multicore setting, MPI for the distributed setup, and CUDA for the manycore architecture.
The following flow diagram explains the working of StarPlat in a simplified manner:
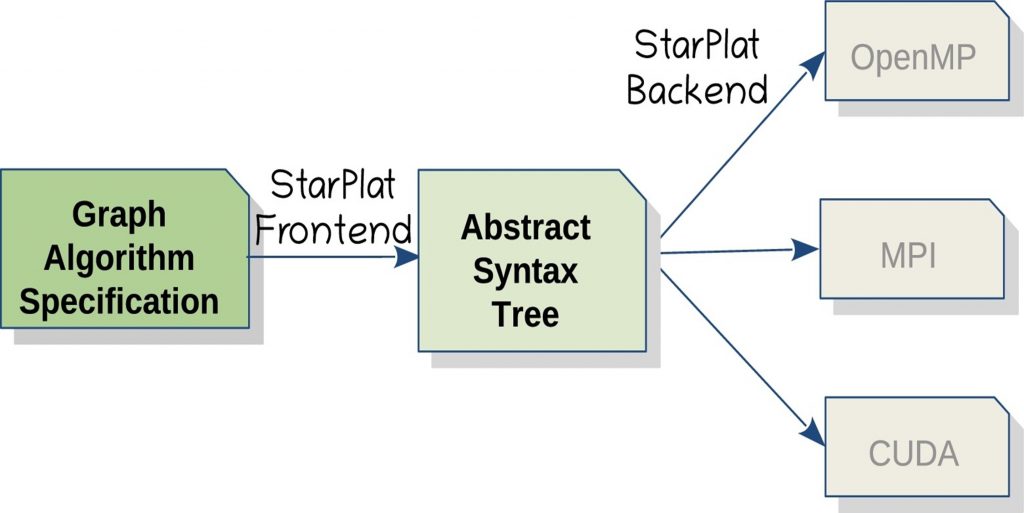
The authors proudly admit that they built upon the insights provided by existing libraries and DSLs, borrowing certain constructs from these frameworks, while providing their own. The code generated was competitive to these frameworks in terms of performance.
The performance of the new code generated was validated experimentally with a range of large graphs, and four different graph algorithms. The generated code was found to be comparable to the hand-tuned and generated implementations of existing frameworks and libraries.
The next step would be to develop graph algorithms to build solutions that are versatile to support multi-platform development. The future direction of StarPlat would be to improve the portability of the solution to support other backends, and to enable automatic code generation for heterogeneous architectures.
There are a few important points to note regarding this study:
- StarPlat technology is patented.
- It was originally funded by India’s National Supercomputing Mission and then by Qualcomm Innovation Fellowship.
- StarPlat is open source.
- StarPlat is featured by Intel.
Dr. Unnikrishnan Cheramangalath, Assistant Professor from the Department of Computer Science and Engineering, Indian Institute of Technology (IIT) Palakkad, Palakkad, Kerala, explained the importance of the authors’ work with the following comments: “Fixed point computation is a mandatory optimization to extract performance in graph algorithms as the diameter of the graph is significantly smaller than the number of vertices in all real world graphs. Reducing redundant and unwanted computation aids in boosting the performance of graph algorithms. Programming all the above optimizations for distributed systems with CPUs and GPUs using native programming languages like C/C++, CUDA and MPI library is challenging and error prone.
The frontend of the StarPlat provides easy abstractions making it easy to program graph algorithms with optimizations for distributed systems with CPUs and GPUs by providing (i)Node, Edge, and Graph as data types (ii) constructs fixedpoint, filter, PropNode etc. (iii) reduction operations (iv) efficient code generator for heterogeneous backends. The StarPlat DSL is versatile and novel. And with its code generator, it is able to convert one program to multiple backends: CPUs, GPUs, and distributed systems. An SSSP program in StarPlat takes around twenty lines of code and the same program can be used for CPU, GPU, and distributed system. This will require few hundred lines of code if programmed with C/C++ & OpenMP, CUDA, and MPI. The Starplat DSL reduces the programming effort very significantly. The experimental evaluation and survey done on StarPlat DSL makes it clear that StarPlat DSL is novel, versatile, and eases program productivity without compromising on the performance.”
Article by Akshay Anantharaman
Click here for the original link to the paper









