Perfecting driverless cars still poses a challenge as there is yet to be a flawless driverless vehicle. But this has not deterred researchers from trying further.
For a perfect driverless vehicle, knowledge of the traffic, and navigating through the unpredictability of traffic is a major aspect that needs to be perfected. Traffic classification is one underlying task for driverless vehicles and varying traffic conditions from place to place makes it challenging to obtain a general traffic classification framework.
In developed countries, the traffic is said to be of a homogeneous and lane-disciplined in nature, that is, not much variation in the type of vehicles and they all follow the lanes. However, in developing countries like India, the traffic is heterogeneous and laneless. This sort of traffic consists of a variety of vehicles like two-wheelers, three-wheelers, cars, trucks, buses etc., without any lane discipline, leading to more challenges.
Traffic data can be classified using a variety of sensors, such as cameras and inductive loop detectors (ILD). However, these techniques have drawbacks. Camera data can be challenging to process based on the lighting conditions, and ILDs are limited to specific locations.

In this study, the authors Mr. Prajwal Shettigar J, and Prof. Arun K. Tangirala from the Department of Data Science and Artificial Intelligence, Robert Bosch Centre for Data Science and Artificial Intelligence, Indian Institute of Technology (IIT) Madras, Chennai, India, and Prof. Lelitha Devi Vanajakshi from the Department of Civil Engineering, Robert Bosch Centre for Data Science and Artificial Intelligence, Indian Institute of Technology (IIT) Madras, Chennai, India, have used a perception based sensor called Light Detection and Ranging (LIDAR), to classify traffic data for Indian urban traffic. LIDAR uses light to measure distances to the surrounding objects. It produces a three dimensional image of the surroundings in the form of a point cloud as shown in the Figure below. This work introduces a generalized classification framework based on traditional 3D point cloud processing algorithms.
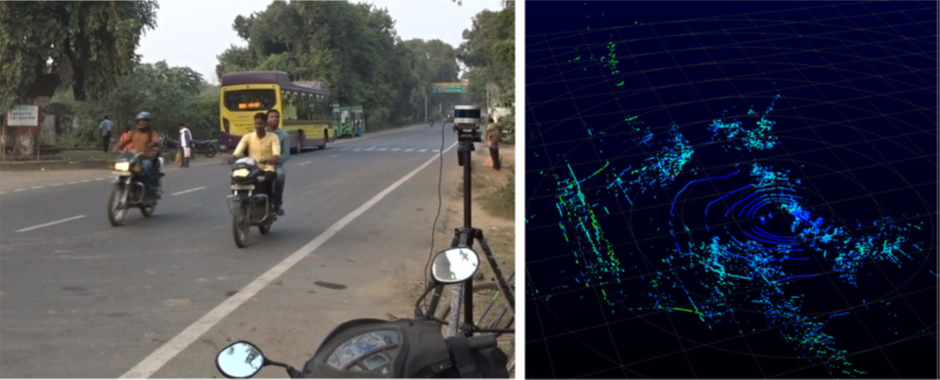
Fig: LIDAR setup (left) and single frame of LIDAR point cloud (right)

Fig: Car used for LIDAR
The advantages of LIDAR-based systems are that they are better than cameras in low light, work well under varying weather conditions, and can be implemented for both static and dynamic applications, meaning they can be at one location or can be mounted on vehicles.
The proposed LIDAR-based traffic classification framework has three stages; first, the clusters are extracted through preprocessing techniques. In the second stage, the features are extracted from these clusters, which are used to predict the classes in the final stage using a multiclass machine learning (ML) model.
The model classifies the samples into 5 classes – pedestrian, two-wheeler, three-wheeler, automobile, and bus/truck, based on 7 handpicked interpretable features representing dimension, orientation, distance, density, and shape.
A variety of clustering algorithms was implemented on the dataset to obtain the most accurate traffic data classification framework. It was found that density-based spatial clustering of applications with noise (DBSCAN) and ground segmentation by m-estimator sample consensus (MSAC) gave the best clustering output.
For the classification problem, the adaptive boosting algorithm (AdaBoost) was shown to have the highest accuracy. The accuracy was further enhanced by data-refining techniques such as skewness reduction and region-of-interest boundary selection.
The final model had an accuracy of 98.4 %. The results show that the framework is well-suited for applications that employ multiclass classifiers for heterogeneous and laneless traffic.
Prof. Anuj Sharma, Professor of Civil Engineering from Iowa State University College of Engineering, Iowa, United States, gave his analysis of the work done in this paper with the following comments: “This paper presents a framework for classifying traffic data using LIDAR, focusing on Indian urban traffic. The process is organized into clear stages: preprocessing, feature extraction, and classification. The authors compared different clustering methods and found that the combination of MSAC and DBSCAN gave the best results. The AdaBoost model achieved a high F1 score of 0.969, showing its effectiveness. This work can be seen as a first step toward developing collision avoidance systems under mixed traffic conditions.”
Article by Akshay Anantharaman
Click here for the original link to the paper